Embedding the Optimization Agent
Integrating the Optimization Agent as an "Optimization Job"
Cloud and inference platforms typically offer different ways to deploy models, but both approaches come with limitations when it comes to optimization:
Model Endpoints
(eg: Nebius AI Studio)
These come with infrastructure-optimized deployment options. They may offer a lightweight "fast" variant, but software inference optimization is often based on standalone FP8/FP16 precision or basic compilation and rarely combines multiple techniques for deeper gains.

Inference Engines
(e.g., AWS SageMaker)
These services provide a suite for deploying your own endpoint and support individual jobs for compilation, batching, or quantization. However, they usually lack a unified, fully-featured optimization workflow that combines techniques to maximize efficiency.

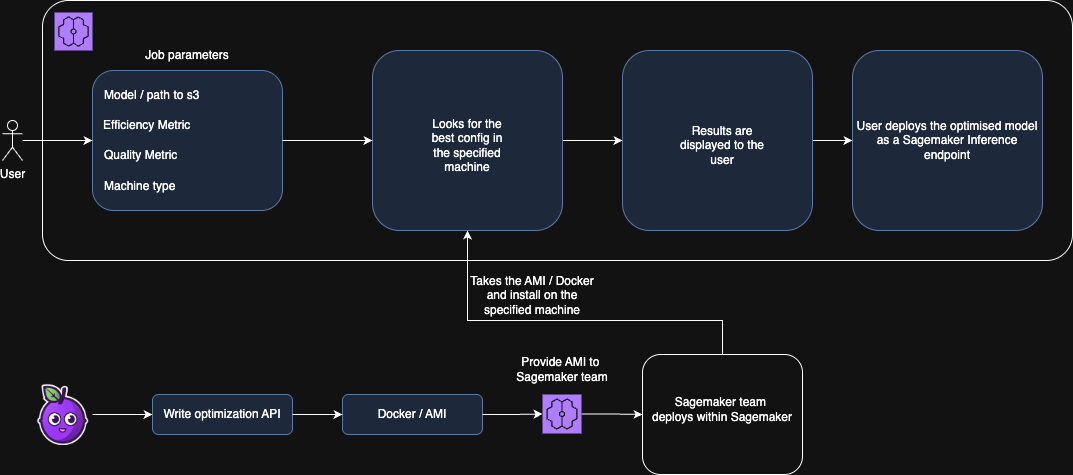
In both cases, Pruna’s Optimization Agent plugs in as an "Optimization Job" (visible or not to the end-user) to power a proper fast mode built for the best dollar-per-output and dollar-per-second ratios.
If you want to expose some optimization choices to your users, you can integrate a simple UI that:
Compare optimization options side-by-side
Recommends the best variant based on hardware, budget, or use case
Let users choose their preferred version before deployment
👉 The following diagram summarizes this flow: