50 optimization algorithms, 10 methods
Pruna’s core feature is its library of 50+ optimization algorithms, organized into 10 methods, such as quantization and pruning, that can be combined to maximize efficiency gains.
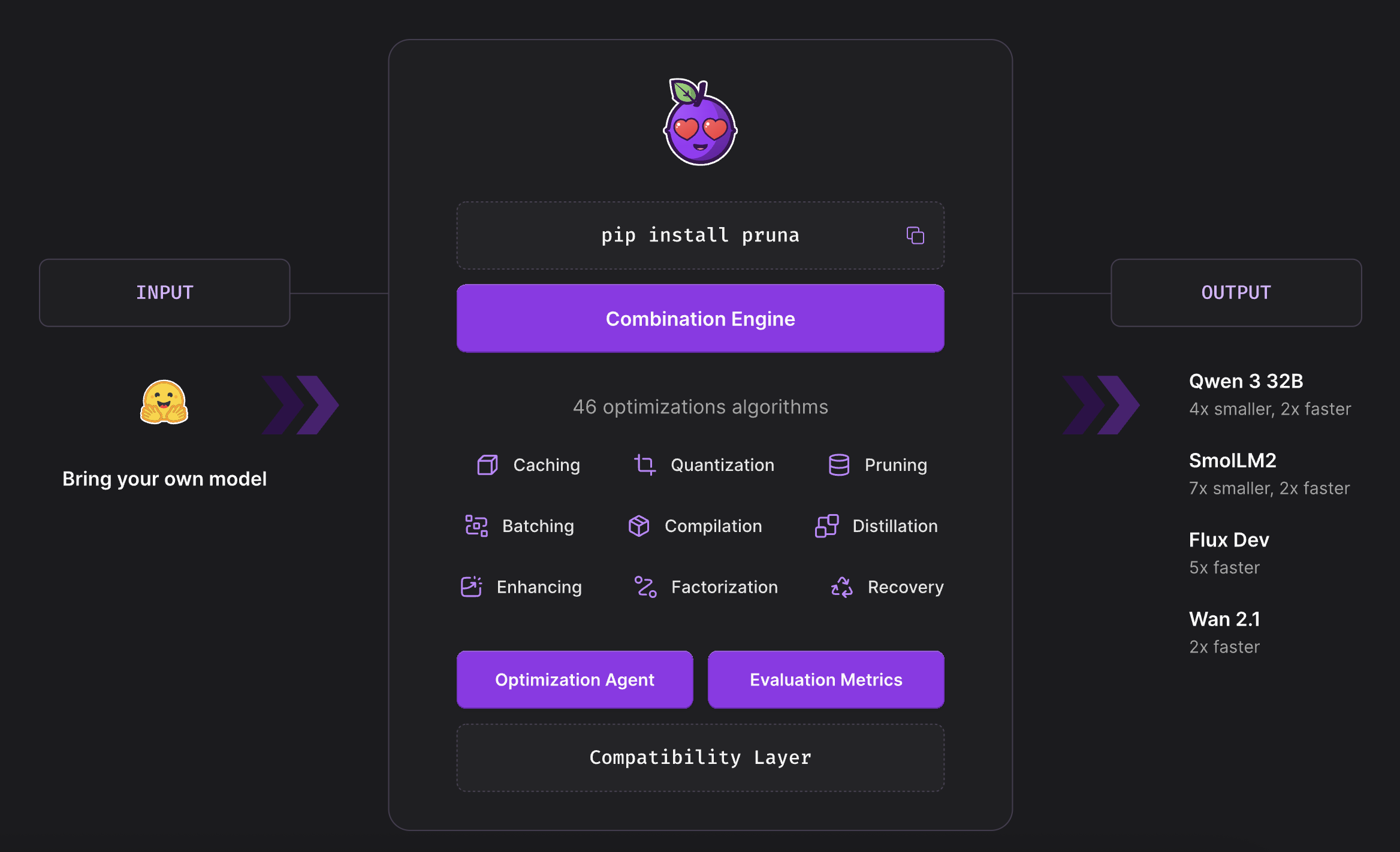
Here is a general description of each technique:
Pruning: removes less important or redundant connections and neurons from a model, resulting in a sparser, more efficient network.
Quantization: reduces the precision of the model’s weights and activations, making them much smaller in terms of memory required.
Batching: groups multiple inputs to be processed simultaneously, improving computational efficiency and reducing overall processing time.
Enhancing improves the quality of the model’s output. Its uses range from post-processing to test-time compute algorithms.
Caching stores intermediate computation results to speed up subsequent operations. It is particularly useful in reducing inference time for machine learning models.
Recovery: restores the performance of a model after compression.
Factorization: batches several small matrix multiplications into one large fused operation, which, while neutral on memory and raw latency, unlocks notable speed-ups when used alongside quantization.
Distillation: trains a smaller, simpler model to mimic a larger, more complex model.
Compilation: optimizes the model for specific hardware.
For a deeper understanding of each method's, you can read this blogpost "An Introduction to AI Model Optimization Techniques"