Pruna and vLLM
To explain how Pruna works VS vLLM, here is how to picture things:
→ vLLM optimizes the environment
→ Pruna optimizes the model
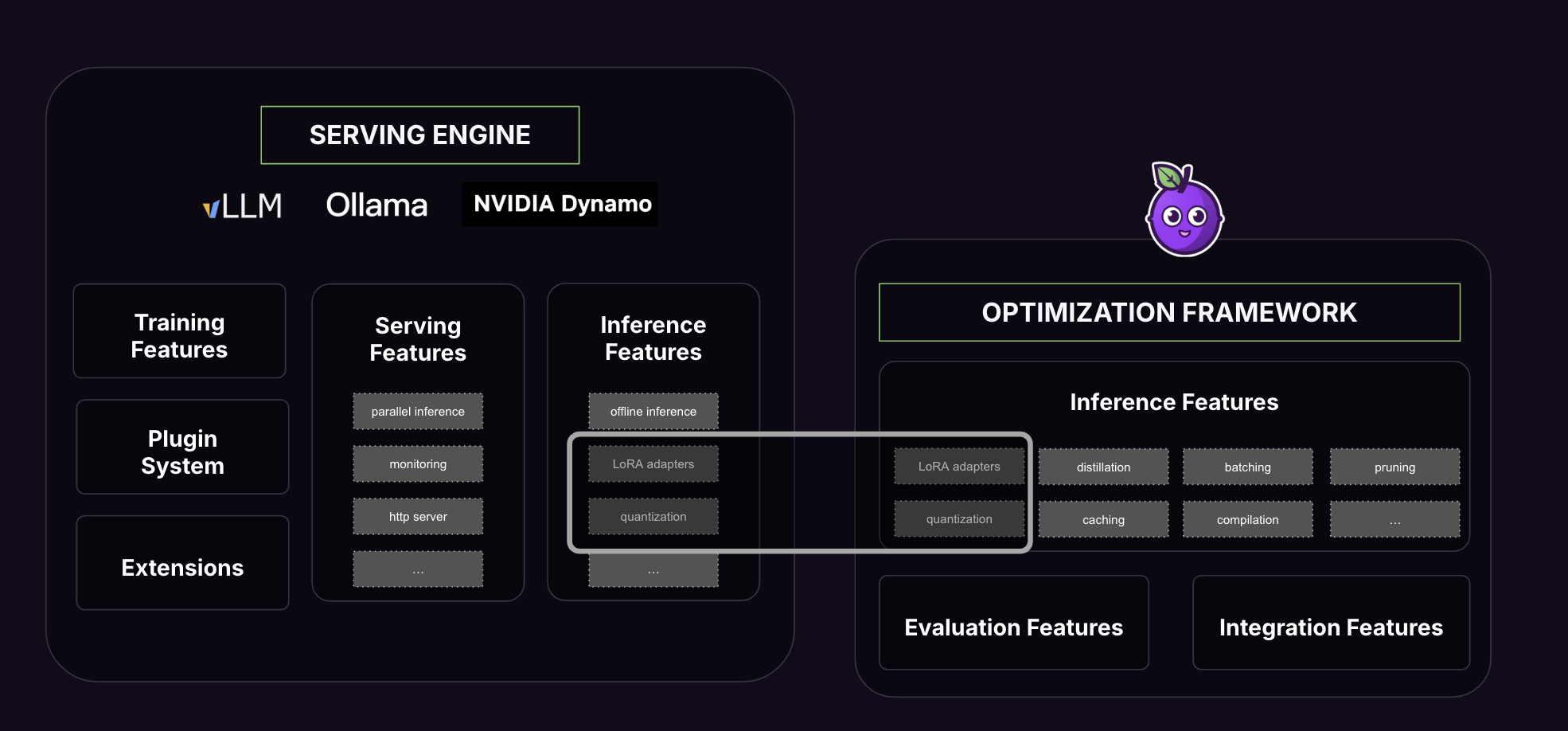
As a quick reminder, vLLM originated from a research paper called PagedAttention, which focuses primarily on distributed inference. Most of their engineering efforts and product value lie in distributed serving, production-level throughput, and environment-level configuration. In other words, infrastructure-focused optimization.
vLLM enables optimized models only if they fall within the scope of supported optimization algorithms, which is quite limited today. In practical terms, you can load a model optimized by Pruna (possibly with LoRA adapters) only if it uses one of these quantizers: AutoAWQ, BitsAndBytes, GPTQ, or TorchAO.
However, a key limitation is that vLLM doesn’t support other optimization types, such as pruning, compilation, or more advanced combinations (like TorchAO + torch.compile). That’s where Pruna comes in: we’re not limited to one type of optimization. We orchestrate multiple algorithms together, and that’s the edge you won’t get from serving platforms alone.
1. Is using Pruna on vLLM currently compelling?
According to our recent benchmark on Llama3.1-8B, the answer is yes. While there are minor benefits (e.g., we’ve cleaned up the TorchAO codebase to make it slightly more usable), the core value of Pruna lies in combining optimization algorithms. The impact is limited since this combination isn’t yet usable within vLLM.
2. Can Pruna produce higher-performing LLMs than vLLM?
Our approach involves method combinations, an optimization agent for automated search, and evaluation metrics to guide the process. This gives us a strong advantage in improving performance.
This is especially true for autoregressive models, which are gaining momentum. Serving platforms like vLLM aren’t likely to offer compatible optimization algorithms anytime soon. That said, our focus isn’t on optimizing the serving environment itself. Pruna should be used alongside other components in your stack.
3. How should you consider integrating Pruna into your stack?
Suppose you’re using more flexible serving engines (like AWS SageMaker), with more room to adapt to specific models or use cases. In that case, Pruna can be the optimization layer, complementing your broader infra setup.
In practical terms, you can load a model optimized by Pruna (possibly with LoRA adapters) only if it uses one of these quantizers: AutoAWQ, BitsAndBytes, GPTQ, or TorchAO.
Our team is working on improving compatibility between Pruna and VLLM.