Optimization Agent
The Optimization Agent is Pruna’s answer to efficient, intelligent model compression and deployment. It offers two core capabilities: flexible optimization workflows and seamless integration with inference platforms.
Manual vs. Automated Smashing
You can compress models with Pruna in two ways:
Manual Smashing
Manual mode gives you granular control. You handpick the compression algorithms and tune every hyperparameter. This approach is for expert ML engineers who know exactly what they want and need to squeeze out every drop of performance. The trade-off? You need deep technical knowledge, and you risk missing out on synergistic combinations unless you’re thorough.
Automated Smashing
Let the Optimization Agent do the heavy lifting. Just load your base model, define your evaluation metrics, and launch the agent. It will:
Detect which compression techniques fit your model and hardware.
Search for the best combinations of algorithms.
Tune hyperparameters to hit your quality, speed, and memory goals.
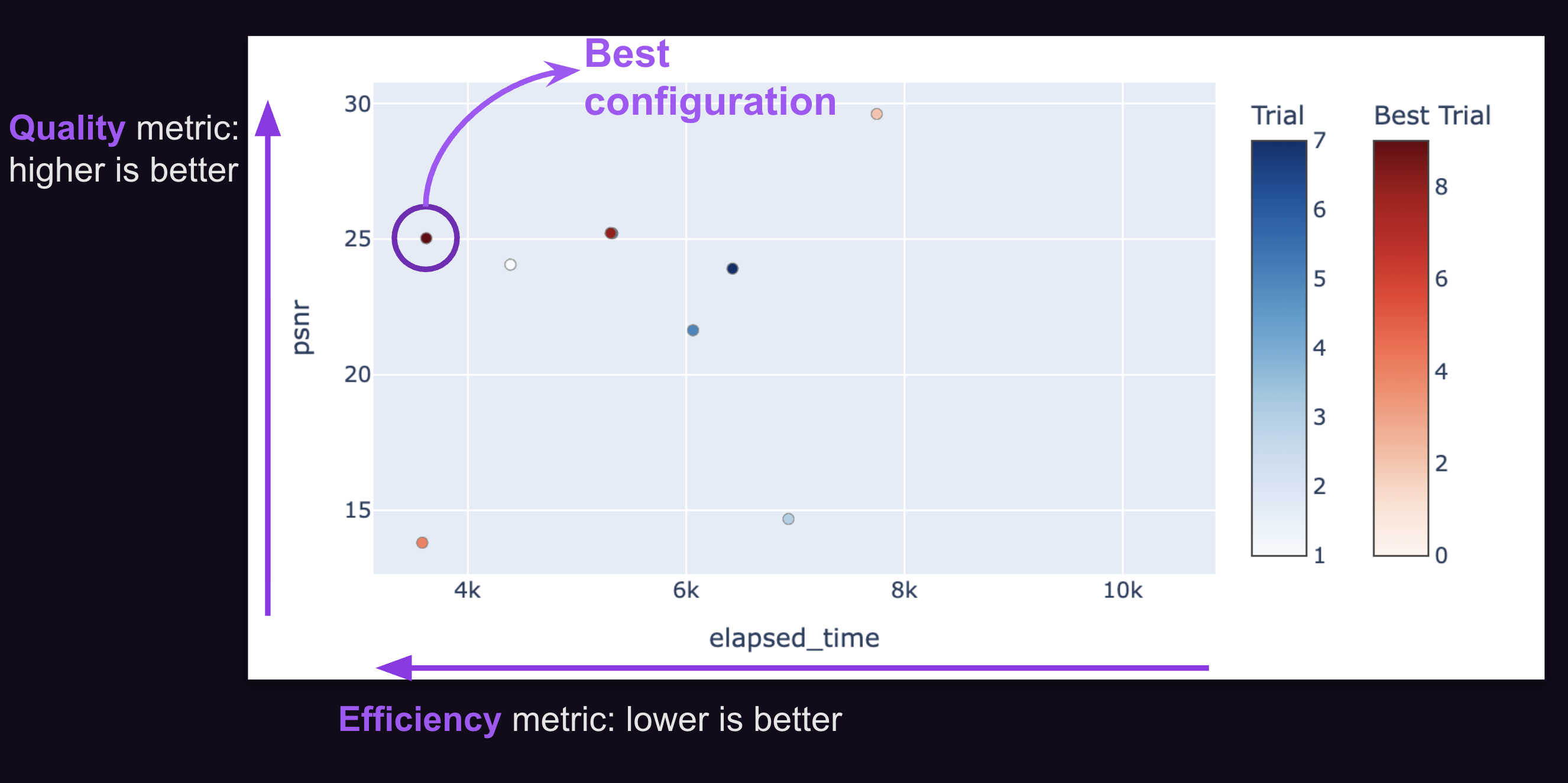
Once optimization is done, results are visualized on a Pareto front plot, so you can see the trade-offs and pick the best configuration for your needs.
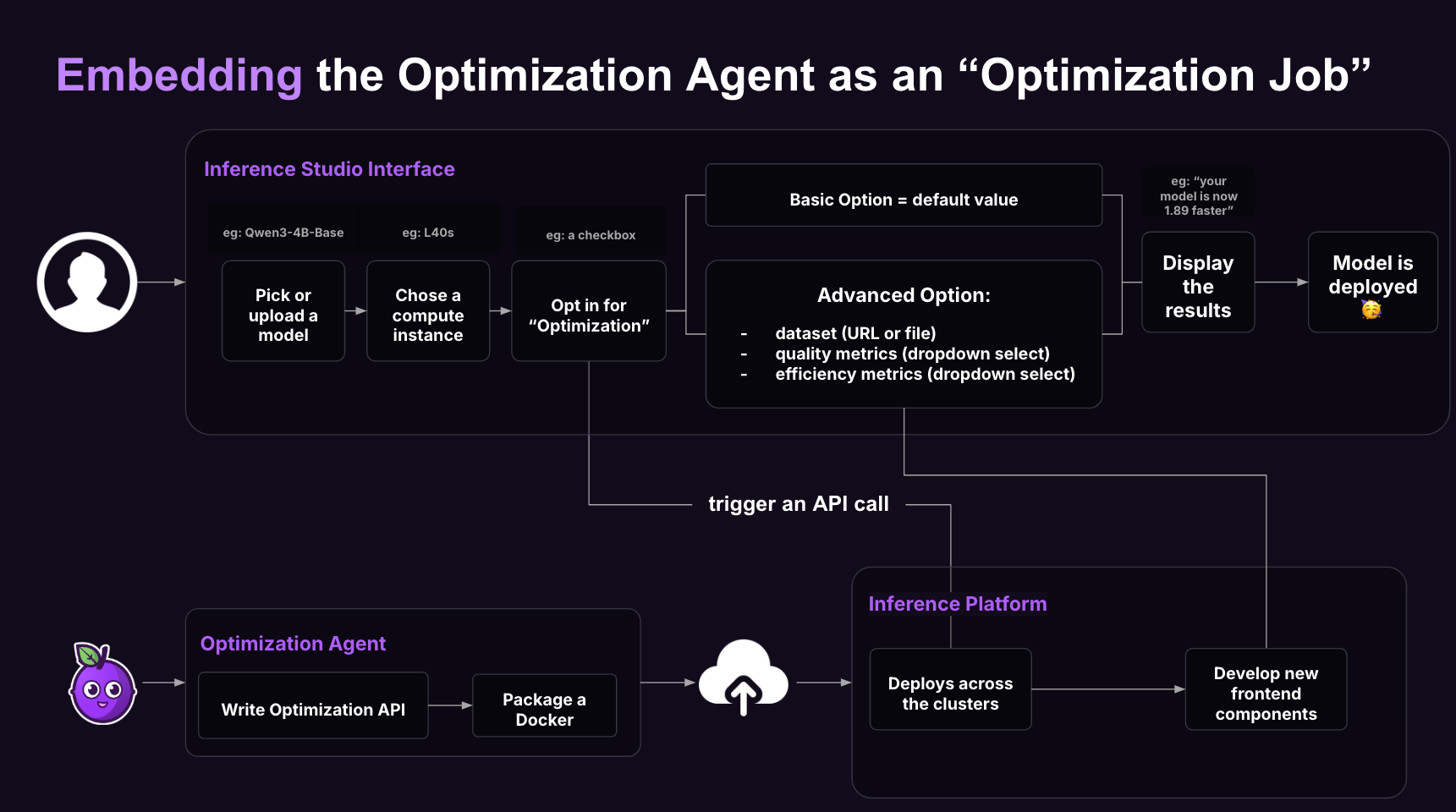
Embedding the Optimization Agent as an "Optimization Job"
Pruna’s Optimization Agent plugs into inference engines (like AWS SageMaker) as an “Optimization Job.” Unlike standard deployment tools that only offer basic optimizations (FP8/FP16, quantization), Pruna combines multiple techniques for deeper efficiency gains.
You can expose optimization options via a simple UI, letting users:
Compare variants side-by-side.
Get recommendations based on hardware, budget, or use case.
Choose their preferred version before deployment.
In short: The Optimization Agent automates, streamlines, and supercharges ant model optimization and deployment, whether you want a push-button experience or advanced settings.